
Klassische HTTP-basierte-APIs sind häufig synchron. Auf eine Anfrage folgt prompt eine Antwort. Nicht immer sind Antworten, wie im Falle unseres Kunden, jedoch sofort verfügbar, z. B., weil noch externe Systeme angefragt werden müssen. Das API ist also asynchron. Doch wie kann ein HTTP API asynchron abgebildet werden, wenn das HTTP-Protokoll doch konzeptionell synchron ist?
Wenn die Daten schon da sind
Normalerweise passieren Daten, damit sie von einem System in ein anderes gelangen, immer eine Schnittstelle (API). Klassischerweise ist diese HTTP-basiert, wie auch in diesem Fall. Das bedeutet, dass, um Daten anzufragen, ein HTTP Request gesendet wird, wie in Abbildung 1 gezeigt.
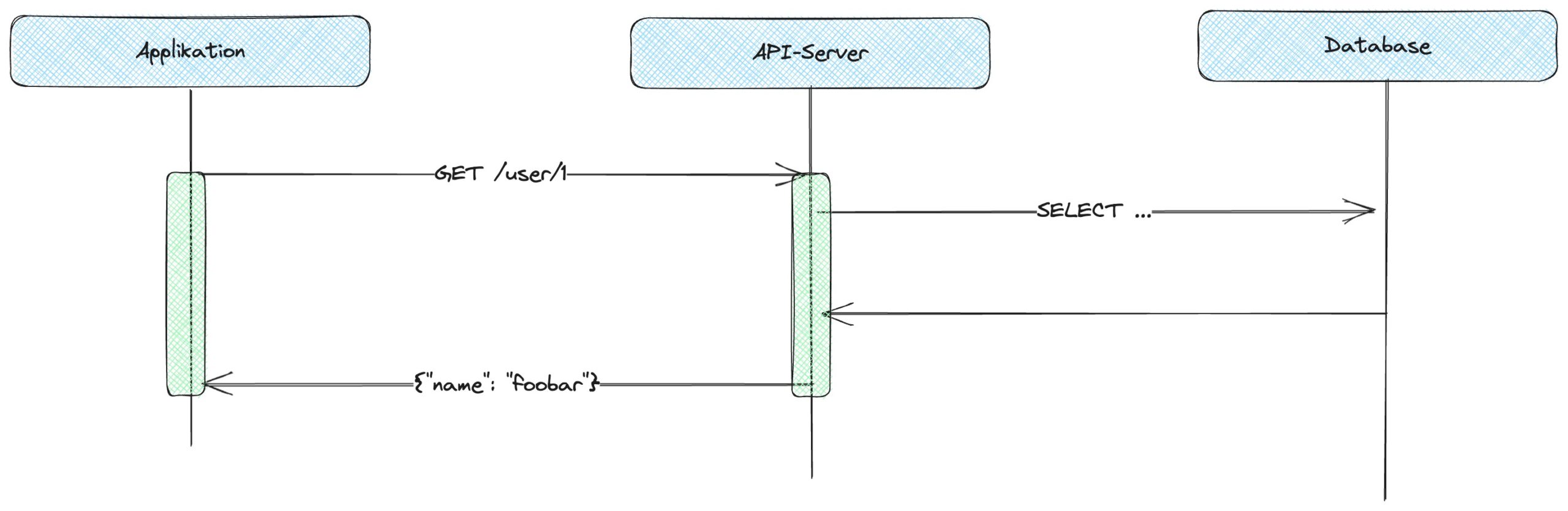
Abb 1: Synchrones API
Das Web-API eines Systems übersetzt diese Anfrage z. B. in eine SQL-Abfrage, transformiert das Ergebnis in ein Serialisierungsformat, wie beispielsweise JSON – manchmal sogar HTML oder XML –, und sendet dem Anfragenden das Ergebnis. Diese Art von Prozess hat allerdings eine Implikation: Der gesamte Prozess blockiert, weil er synchron ist. Ist die konsumierende Applikation des API beispielsweise ein Browser, sieht der Nutzer für die gesamte Laufzeit eine Ladeanzeige.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Erst wenn das API die Antwort geliefert hat, wird in der Applikation weiterverfahren. Sowohl Applikation als auch API müssen eine Verbindung offenhalten, bis die Daten übertragen wurden. Der Zustand des Prozesses, erkennbar durch die grünen Balken in der Spalte der Applikation, wird damit (kurzzeitig) über die TCP-Verbindung abgebildet. Solch eine Kommunikation des API ist glücklicherweise relativ trivial und kurzlebig. Diese Art der Kommunikation ist konzeptionell synchron und für die meisten Web-APIs ausreichend.
Die Daten warten noch
Komplexer ist es, wenn der API-Server nicht mit einer eigenen Datenhaltung kommuniziert, die Daten direkt bereithält, sondern ein komplexerer Prozess existiert, der eine Antwort erst viel später – asynchron – liefert. Im folgenden Beispiel also das Anlegen einer Bestellung. In diesem Falle ist es notwendig, für den API-Server ein API bereitzustellen, das diese Asynchronität unterstützt. Die wohl simpelste Möglichkeit, Daten eines asynchronen API bereitzustellen, ist die über die Methode Polling (Abb. 2).
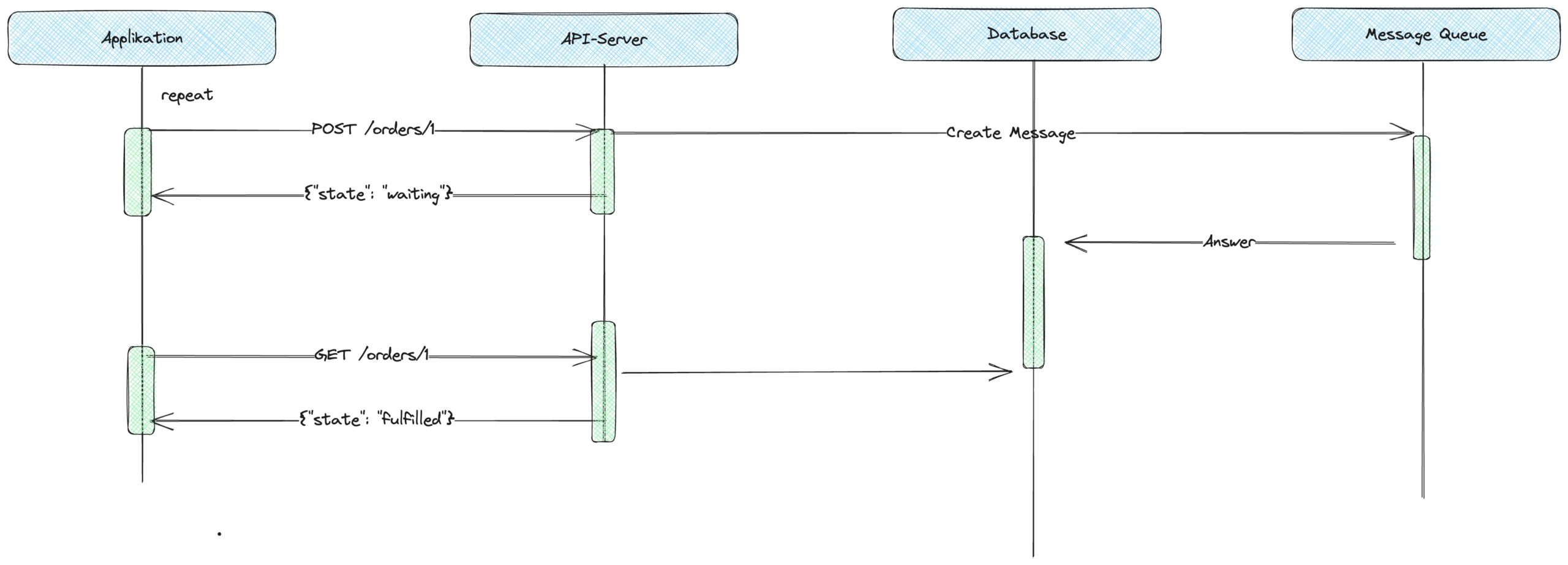
Abb. 2: Polling: das wiederholte Anfragen des Zustands
Beim Polling führt eine Applikation im Beispiel ein Erstellen von Daten aus und erhält dabei den aktuellen Zustand, während auf einem asynchronen externen System (z. B. einer Message Queue) eine Anfrage gestellt wird. Asynchronität bedeutet in der Implementierung immer, dass es einen Zwischenzustand („Wartend“) gibt, der ein nicht vorhandenes Ergebnis abbilden kann. Nach dem Erstellen erhält der Konsument in der Regel deshalb einen Datensatz, der eben diesen Zustand enthält. Ob das Ergebnis im Zustand „Wartend“ ausreichend ist, kann nur der Konsument des API selbst entscheiden. In den meisten Fällen ist das nicht der Fall. Der Zustand der Kommunikation bleibt deshalb weitgehend dem Konsumenten des API überlassen, denn dieser muss entscheiden, ob alle Daten vorhanden sind oder ob weitere Aktualisierungsschritte eingeleitet werden müssen.
Genau für diese weiteren Aktualisierungsschritte muss der API-Server einen zweiten Endpunkt implementieren, der den aktuellen Stand einer Bestellung (Order) für den aktuellen Zustand abfragbar macht. Der Konsument muss also selbst einen Mechanismus implementieren, innerhalb dessen er wiederholt den API-Server anfragt, je nachdem, ob die Daten aktuell genug sind. Im Beispiel wird die Bestellung mit der ID 1 wiederholt angefragt.
Die Schwierigkeit bei einem solchen Modell ist das Finden eines geeigneten Intervalls. Es ergibt wenig Sinn, bei einem Prozess, der Tage in Anspruch nimmt, im Minutentakt eine Aktualisierung zu erfragen. Ein API-Server muss deshalb bei tendenziell vielen Clients viele „leere Nachrichten“ verarbeiten. Der Vorteil liegt aber klar auf der Hand: Es ist Aufgabe des Clients, die aktuellen Daten zu erhalten. Der API-Server ist im Kommunikationsprozess relativ zustandslos.
Verbindungen reduzieren durch Long Polling
Eine Alternative für das regelmäßige Polling mit Intervall ist das Long Polling (Abb. 3). Dabei wird nach einer Anfrage die technische Verbindung so lange offengehalten, bis das Ergebnis letztlich eintritt, ähnlich wie es von TCP-Verbindungen bekannt ist.
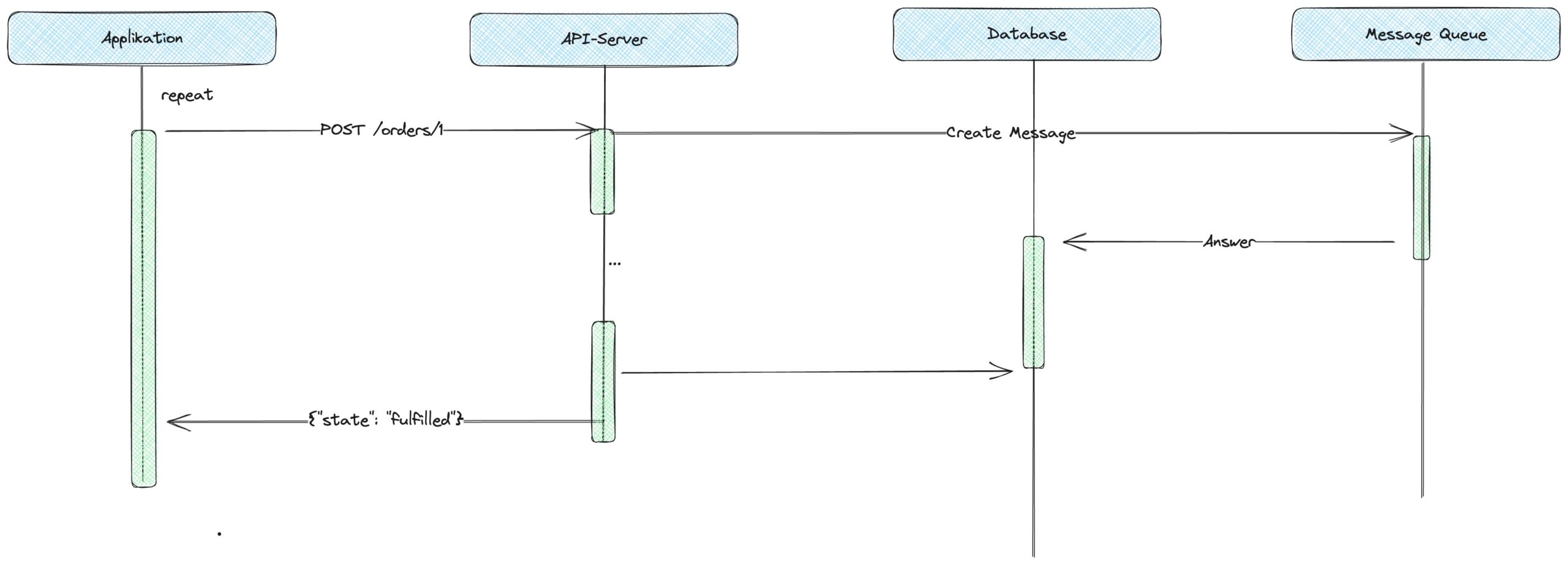
Abb. 3: Long Polling: Verbindungen reduzieren
Diese Technik impliziert, dass der API-Server sehr lange eine HTTP-Verbindung offenhalten muss. Das kostet Speicher und muss von der Infrastruktur und deren Konfiguration unterstützt werden. Sowohl der Konsument als auch der API-Server, der die Daten bereitstellt, müssen eine Verbindung offenhalten bzw. regelmäßig erneuern wie beim Polling. Auch bei dieser Technik muss der Konsument des API einen Zustand vorhalten, der ein erneutes Abfragen des API anspricht. Es wird also ein technisches Problem gelöst, nicht aber der konzeptionelle Umstand der Datenverwaltung.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Verbindungen minimieren durch Webhooks
Da es sich um einen Anwendungsfall von zwei vertrauenswürdigen Applikationen – Backend genannt – handelte, ist noch eine weitere Art von API möglich: Webhooks (Abb. 4).
Die Idee von Webhooks ist es, einen Kommunikations-Overhead der zuvor genannten Techniken zu mitigieren und stattdessen den Umstand auszunutzen, dass sowohl der Konsument als auch der Anbieter des API selbst eine Schnittstelle anbieten kann.
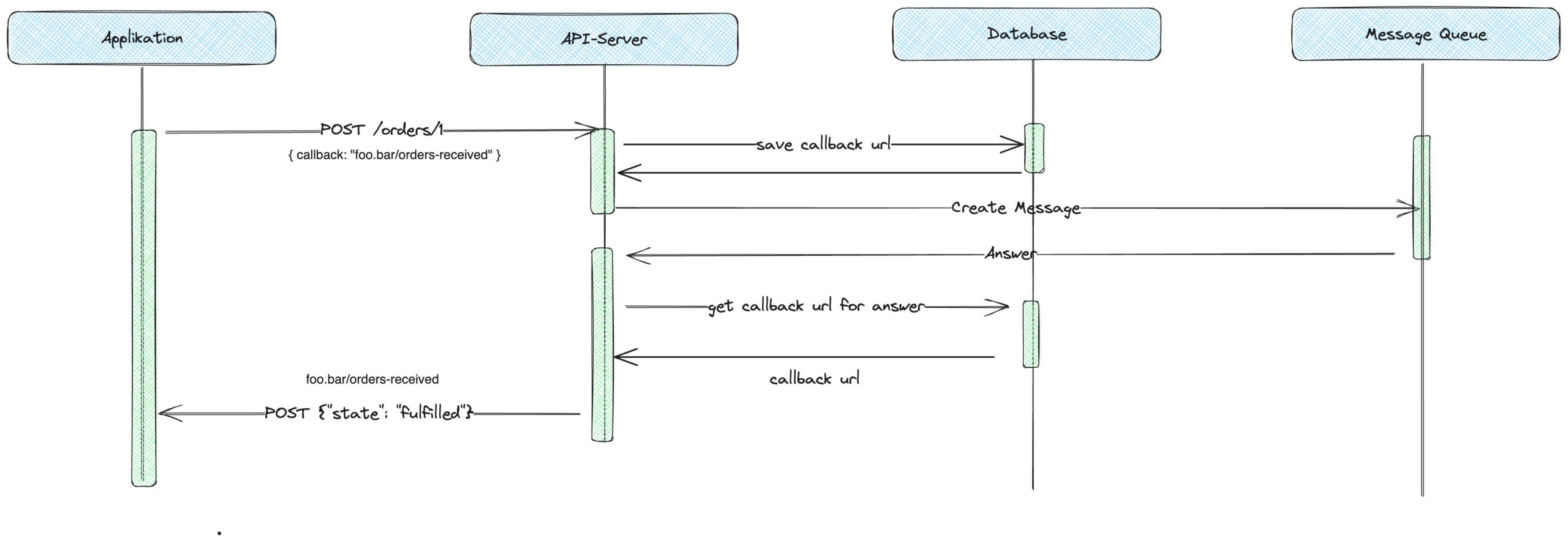
Abb. 4: Webhooks
Der Konsument des API bietet bei diesem Ansatz selbst ein beliebiges Callback API an – im Beispiel erreichbar unter dem URL /orders-received. Genau diesen URL teilt der Konsument beim Erstellen der Anfrage mit. Im Bild also foo.bar/orders-received. Der API-Server selbst speichert diesen in einer beliebigen Datenhaltung ab und stellt die Anfrage an das asynchrone System. In diesem Falle die Message Queue.
Erhält der API-Server eine Antwort auf die initial gestellte Anfrage durch die Message-Queue, kann dieser durch die zuvor vorgehaltene Abbildung von erstelltem Objekt und Callback-URL das entsprechende API des Konsumenten aufrufen. Eins ist damit klar erkennbar: Im Gegensatz zum Polling ist es bei Webhooks die Aufgabe des Servers, die Daten an den Konsumenten zu liefern. Die Zuständigkeiten haben sich damit verändert.
Durch eine Kommunikation über Webhooks werden die Nachteile des Polling vermieden. Diese Technik ist aber nicht überall einsetzbar – schließlich kann nicht jeder Konsument eines API, z. B. Browser, auch selbst ein API anbieten. Diese Technik ist damit nur eingeschränkt nutzbar. Ist der Konsument ein Browser, ist ein solches API kaum abbildbar, da es keine mir bekannte Möglichkeit gibt, dass der Browser als zuverlässiger Server fungiert.
Natürlich hat diese Art der Kommunikation auch noch weitere Nachteile. Beispielsweise ist der Konsument gezwungen, ein Callback API anzubieten und wird damit vom Konsumenten eines API zum Anbieter eines API.
Ist der Konsument des API unzuverlässig, z. B., weil die Applikation regelmäßig abstürzt, hat der API-Server nun außerdem die Aufgabe, gewisse Fehlertoleranzen zu implementieren. Das kann zum Beispiel durch Retry-Mechanismen geschehen – Aufgaben, die beim Polling-Ansatz nicht existieren würden, da der Client dort reiner Konsument ist und es sich um zustandslose Beziehung handelt.
Fazit
Die meisten HTTP-basierten Schnittstellen sind Request-Response-basiert und damit relativ trivial umzusetzen. Auf eine Anfrage folgt eine Antwort. Schwieriger wird es, wenn Asynchronität ins Spiel kommt. Für die Asynchronität muss ein Mechanismus her. In verteilten Systemen wird häufig das erneute Anfragen von Daten, genannt Polling, angewendet, um Daten regelmäßig zu untersuchen. Durch das Long Polling kann diese Technik dahingehend verändert werden, dass ein ständiges Auf- und Abbauen von Verbindungen verhindern.
Bei einer Backend-zu-Backend-Kommunikation wird häufig auf Webhooks gesetzt. Webhooks machen einen asynchronen Prozess Event- statt aktualisierungsgetrieben. Dadurch werden unnötige Kommunikationswege vermieden. Das ist nicht komplett kostenlos: Der API-Konsument ist nun in der Pflicht, selbst ein API bereitzustellen, und der API-Anbieter muss den Zustand der Kommunikation – also „wer ist an welchen Daten interessiert?“ – übernehmen.
Eins ist allerdings klar: Bei beiden Ansätzen muss auch die implementierende Seite des Clients Hand anlegen, sei es in Form einer Aktualisierungsschleife oder in Form eines eigenen HTTP API.




